
How to Optimize Content for Perplexity AI: Complete Guide June 2026

By Bennett Cohen
Get Maintouch
Turn search and AI visibility work into a repeatable growth system.
Perplexity visits around ten pages per query. It names three to four in the answer and ignores the rest. That's it.
Getting retrieved isn't the goal. Citation is. Plenty of pages clear the crawl, sit in Perplexity's context window, and still never show up in the answer. The writer rarely finds out which gate closed.
The five filters break out cleanly. I'll walk through each one and the patterns that move a page from visited to named.
TLDR:
- Perplexity cites 3-4 sources per query and ignores everything else. Sites need a 0.75+ quality score to clear five gates: retrieval, relevance, quality, freshness, and authority.
- Content loses citation eligibility after 90 days. Refresh stats, dates, and examples on that cycle or watch visibility drop without warning.
- Reddit accounts for 46.7% of top citations. Genuine answers with upvotes beat promotional posts that get downvoted.
- Schema markup increases AI answer placement by 2.5x. Sites at DA 40+ get cited 6x more often than lower-authority domains.
- Maintouch automates the 90-day refresh cycles, schema deployment, and citation tracking across ChatGPT, Perplexity, and Google AI Overviews through background agents and API access.
How Perplexity Selects and Ranks Content
Perplexity doesn't hand out positions one through ten. It picks three sources and ignores everything else.
That changes what you optimize for.
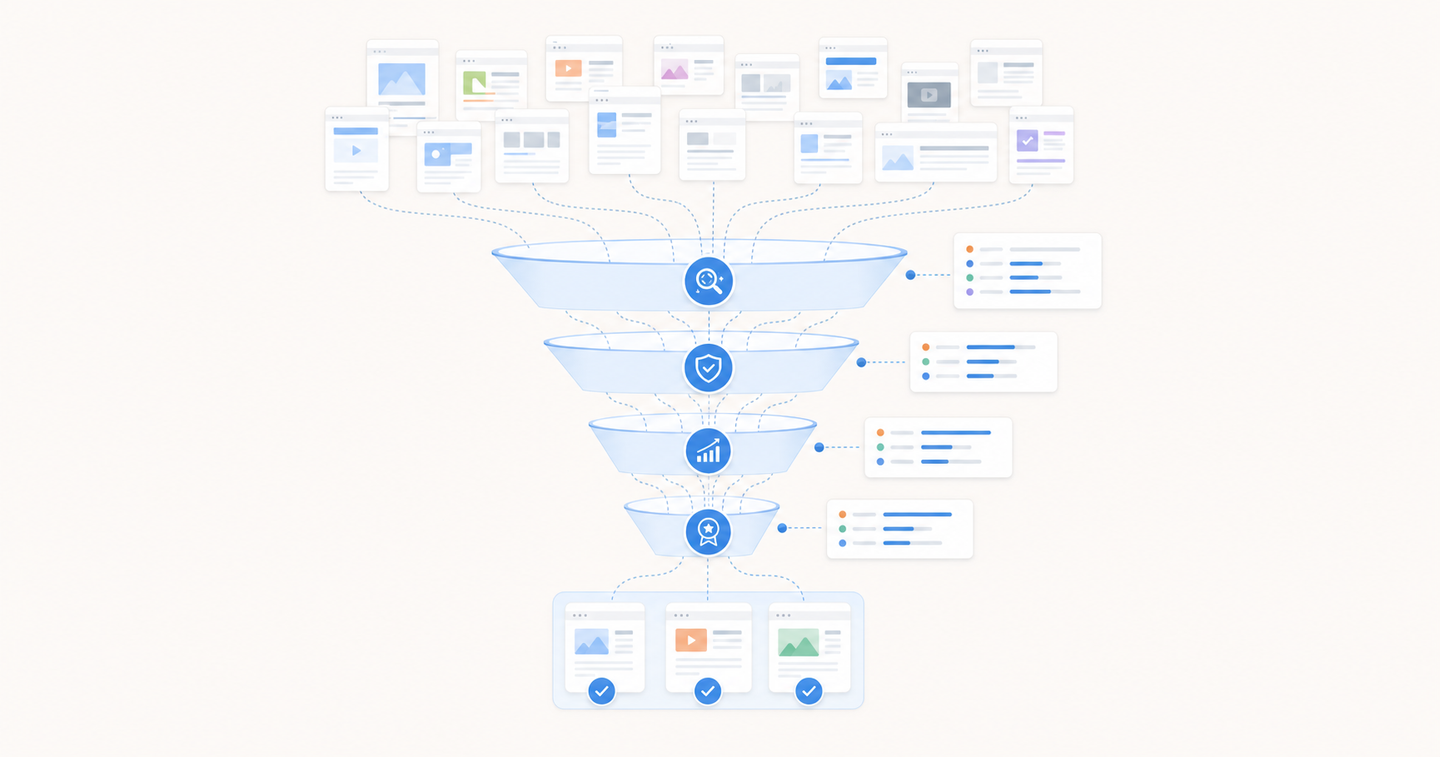
Under the hood, Perplexity reformulates the query, calls Bing's Search API, then filters results through its retrieval-augmented generation system. Based on observed behavior, it visits around ten pages per query but pulls only three to four into the answer.
Five gates stand between you and citation: retrieval, relevance, quality, freshness, and authority. For entity-based searches, Perplexity's L3 reranker decides who makes the cut. Based on observed patterns, content typically needs a quality score around 0.75 for top placements.
The question isn't where you rank. It's whether you survive the filter.
Answer First, Context Second
Front-load the answer. Perplexity extracts opening paragraphs far more often than buried text, so your complete answer needs to sit in the first 100 words. Context comes after.
Traditional intros kill you here. The slow build, the setup, the throat-clearing, all of it works against extraction. Lead with the answer, then add supporting detail.
Three moves help:
- Phrase H2 headers as the actual questions people ask.
- Answer each section's question in its first sentence.
- Keep the answer self-contained so it can be lifted without surrounding context.
You're writing for extraction, not for the slow scroll.
Content Freshness Requirements
Google will rank a good evergreen page for years. Perplexity won't.
Citation eligibility decays fast. Based on observed patterns, content left untouched starts losing visibility after two to three months. Treat 90 days as your refresh cycle. Past that window, pages that used to get cited drop out, and you won't notice unless you're watching for it.
Three habits keep you in the running:
- Put a visible date stamp on the page so recency reads clearly.
- Refresh stats, examples, and dates every 90 days.
- Track which pages stop getting cited, then update those first.
Citation loss is the trigger. By the time visibility craters, you're late.
Building Domain and Topical Authority Signals
Perplexity reads authority on two levels, and you need both.
Domain trust comes first. The retrieval model weights Majestic Trust Flow and Moz Domain Authority heavily, and sites at DA 40 or above get sourced roughly 6x more often, according to HarborSEO's analysis. A high domain score gets you considered. It won't carry you alone.
The second layer is topical depth. Perplexity rewards sources that cover a subject from multiple angles. When your pages reference each other across related topics, those connections compound into a signal that reads as expertise.
How to build it:
- Architect content into topic clusters, with one pillar page anchoring tightly related supporting pieces.
- Link those pages to each other so the cluster reads as one body of work.
- Earn third-party citations from sites that already carry trust in your space.
Work both levers or you're only halfway there.
Reddit and Community Presence Strategy
Perplexity leans on community discussion over polished marketing copy, and the numbers are blunt. Reddit alone accounts for 46.7% of top citations according to Stackmatix's research. If you want to show up in answers, you need to be there.
Genuine participation works. Promotion gets you nowhere.
Four rules:
- Find the subreddits where your buyers ask questions, then read before you post.
- Answer real questions with specific detail. Skip the link drop.
- Disclose when you work for the company you're talking about. Undisclosed shilling gets caught and torched.
- Aim for upvotes, since vote patterns signal quality to Perplexity's filter.
One helpful answer that climbs a thread beats ten thinly veiled ads downvoted to oblivion.
Technical Accessibility for PerplexityBot
Before any of this matters, PerplexityBot has to reach your site.
PerplexityBot crawls separately from Googlebot. A robots.txt rule that blocks non-Google bots makes you invisible to Perplexity no matter how well you rank on Google. Check three things before you spend a minute on content:
- Allow PerplexityBot by name in robots.txt, and don't blanket-block crawlers.
- Keep server response time under 200ms.
- Confirm PerplexityBot hits in your server logs.
Fail the crawl, fail everything.
Structured Data and Schema Implementation
Perplexity can't cite what it can't parse.
Schema markup gives its extraction pipeline structured fields to read directly. Content with proper markup has a 2.5x higher chance of landing in AI-generated answers according to Stackmatix's research. Sites running complete Tier 1 schema see up to 40% more AI Overview appearances.
Four schema types that matter:
| Schema | What it does |
|---|---|
| FAQPage | Maps questions to extractable answers |
| Article | Signals author, publish date, freshness |
| Product | Exposes price, specs, availability |
| Organization | Signals entity identity and trust |
Validate every page through Google's Rich Results Test before it ships. Broken markup gets ignored. Invalid schema is the same as no schema.
High-Multiplier Topic Categories
Perplexity plays favorites.
Content tagged as AI, science, or marketing gets a 3x ranking multiplier according to Nick Lafferty's analysis. The category your page lands in changes your odds before quality even matters.
What gets boosted:
- AI and machine learning
- Scientific research
- Marketing strategy
- Data science
Frame your expertise toward these when the connection is real. Force a category that doesn't fit and the content reads thin. That kills the credibility you're trying to build.
Original Data and Citation-Worthy Statistics
Original data is the one moat competitors can't copy. When you're the only source for a number, Perplexity has no alternative to cite.
Run surveys. Publish case studies. Analyze data nobody else has and put hard figures on it, dated and specific.
Lead the data work like this:
- Lead with concrete stats: exact percentages, sample sizes, dates.
- Build comparison tables with real data points, not vague claims.
- Seed statistics throughout so any extracted passage carries a citable number.
Become the primary source. Citation stops being optional.
Monitoring Citations and Measuring Performance
Ranking checkers won't help you here. You're not tracking position. You're tracking whether Perplexity names you at all.
Run the queries yourself. Ask Perplexity the exact questions your buyers would ask, then write down what comes back.
What to track weekly for competitive topics:
- Which pages got cited and how often across repeat queries.
- Whether you're the primary source or a supplementary mention.
- The context: whether the surrounding sentence reads positive, neutral, or wrong.
Capture a baseline before you change anything. Document your current citation share so you can measure lift later.
Tracking tools cover scale once you outgrow manual checks, but the manual pass teaches you what the answers actually say.
How Maintouch Automates Perplexity Optimization at Scale
Everything above is doable by hand. At ten pages it's tedious. At hundreds it's not realistic.
Maintouch treats SEO and AEO as one workflow. AI chatbots run a web search before they answer, so the same retrieval signals feed Perplexity citations.
Three pieces handle the work:
- The General Agent handles keyword research, content strategy, and on-page work through conversational commands.
- Citation tracking runs as a standalone capability with public API access, monitoring ChatGPT, Perplexity, and Google AI Overviews across 1,000+ concurrent prompt queries.
- Background agents execute the flagged work: content updates, technical fixes, schema, and the 90-day refresh cycles Perplexity's recency weighting demands.
The self-learning engine diffs every human edit against the AI draft, then updates the knowledge base, brand voice, and blog rules automatically. The system learns from your edits instead of forgetting them.
Final Thoughts on Winning AI Citations
Perplexity picks three sources and ignores everything else. Your content either clears the filter or it doesn't exist on the page that matters.
The playbook itself isn't complicated. Answer-first structure, 90-day refresh cycles, and topical authority that reads as real expertise. What breaks most teams is running it at scale, week after week, without dropping pages out of the rotation.
That's the part Maintouch handles. Background agents run the refresh cycles and citation tracking so visibility stops being a side project.
I hope this was useful. If you want to talk through how any of this maps onto your site, shoot me a message and I'll take a look.
FAQ
Can I optimize content for Perplexity without JavaScript?
Yes. Perplexity reads standard HTML and schema markup, so you don't need JavaScript-heavy frameworks to get cited. The system extracts from opening paragraphs, structured data, and clean text content. Focus on front-loaded answers, valid schema, and fast page loads instead of interactive elements.
What's the fastest way to check if PerplexityBot is actually crawling my site?
Check your server logs for PerplexityBot hits, then confirm your robots.txt isn't blocking it by name. Most sites blanket-block non-Google crawlers without realizing Perplexity runs a separate bot. If you're not seeing PerplexityBot requests in your logs, you're invisible to the system regardless of content quality.
How often should I refresh content to stay citation-eligible?
Every 90 days. Perplexity's quality filter decays fast, and pages left untouched past three months quietly drop out of citation rotation even if they ranked well before. Track which pages stop getting cited, then update those first with stat refreshes, fresh examples, and visible date stamps on a quarterly rhythm.
Perplexity vs Google for domain authority signals?
Perplexity weights Majestic Trust Flow and Moz Domain Authority heavily in its retrieval model, while Google has moved toward entity-based and behavioral signals. Sites at DA 40 or above get sourced roughly 6x more often in Perplexity citations, so traditional link-building still matters more for AI search than most people realize.
What schema types actually move the needle for AI citations?
FAQPage, Article, Product, and Organization schema carry the load. Content with proper markup has a 2.5x higher chance of landing in AI-generated answers, and sites running complete Tier 1 schema see up to 40% more AI Overview appearances. Validate through Google's Rich Results Test before publishing: broken markup gets ignored entirely.
Can I track which queries Perplexity is citing my content for?
You need to run the queries yourself or use citation monitoring tools with API access. Check Perplexity directly for your target keywords, then log which pages get cited and in what context. Maintouch tracks citations across ChatGPT, Perplexity, and Google AI Overviews through 1,000+ concurrent prompt queries, but manual spot-checks teach you what the answers actually say before you scale.
How is Perplexity optimization different from Google SEO?
Perplexity runs on Bing's Search API before its retrieval filter kicks in, so traditional domain authority and structured data still matter. The difference is citation threshold: Google ranks hundreds of results per query, Perplexity picks three to four sources and ignores the rest. You're optimizing for answer extraction and quality scoring, not position 8 versus position 12.
Should I optimize existing content or create new pages for Perplexity?
Start with your existing high-authority pages that already rank well in Google. Add front-loaded answers, schema markup, and 90-day refresh cycles to content that's closest to citation eligibility. Creating net-new pages makes sense after you've maxed out citation share on what you already have, not before.
What's the minimum domain authority needed to get cited in Perplexity?
Sites at DA 40 or above get sourced roughly 6x more often, but lower-authority domains can still get cited if they have strong topical depth and original data. The quality score threshold is 0.75 for top placements, and that combines domain trust with content-level signals. Build authority through topic clusters and earned citations instead of waiting to hit an arbitrary DA number.
Does Perplexity penalize AI-generated content?
Perplexity doesn't flag content as AI-generated the way a spam filter would. It scores on relevance, quality, and structure regardless of how you produced it. The filter punishes thin answers, missing context, and outdated information, all of which AI drafts produce at scale if you're not editing them. Write for extraction and keep quality high, regardless of the tool.
How do I know if my competitors are getting cited more than me?
Run the same high-intent queries your buyers would ask, then document who Perplexity names in the answer. Track primary versus supplementary mentions, and note whether competitors get cited for original data or topical authority. If you're consistently invisible on queries you rank for in Google, that's your signal to audit answer structure and schema on those pages.
Can Perplexity cite content behind paywalls or login walls?
No. PerplexityBot crawls like any other bot, so gated content stays invisible. If your best data lives behind a login or paywall, pull key statistics and insights into publicly accessible pages so Perplexity can reach them. You can gate deeper analysis while keeping citation-worthy answers open.
What happens if Perplexity cites my content incorrectly?
Check whether the error comes from ambiguous phrasing or missing context in your source material. If Perplexity misreads your content, rewrite the answer to be more explicit and self-contained in the opening paragraph. There's no citation correction form, so you fix it by making your content harder to misinterpret during extraction.
Turn search into your best growth channel.
Maintouch tracks your visibility across AI and Google, creates and refreshes content, and gets your brand mentioned on the sites that shape discovery.
Book a demo